Medidas de Dispersão
Objetivos com o texto:
- Conhecer as medidas de dispersão
- Compreender a importância das medidas de dispersão
- Aprender a calcular a variância, o desvio-padrão, o erro-padrão e o coeficiente de variação
As medidas de dispersão mostram a variabilidade de um conjunto de observações em relação à região central. Essas medidas indicam se um conjunto de dados é homogêneo ou heterogêneo. Além disso, mostram-se a medida de tendência central escolhida representa bem o conjunto de dados que está sendo trabalhado pelo pesquisador.
Somente a média, por exemplo, não é capaz de dar uma ideia sobre como os dados se comportam, isto é, qual o grau de variabilidade dos valores de um conjunto de dados. Por exemplo, vamos supor que um aluno obteve a média sete, as notas desse aluno nos quatro bimestres poderiam ter sido:

No exemplo 01 não existe dispersão dos dados, todas as observações são iguais a média, no exemplo 02 há pouca dispersão, já no exemplo 03 existe uma grande dispersão dos dados. Dessa forma, é importante medir o grau de dispersão dos dados de um conjunto, por meio das medidas de dispersão.
AMPLITUDE (A)
A amplitude é a diferença entre o maior e o menor valor de um conjunto de dados.

Exemplo: Considerando o exemplo anterior das notas do aluno com média sete, temos as seguintes amplitudes:
Exemplo 01: A = 7–7 = 0
Exemplo 02: A = 8–6 =3
Exemplo 01: A = 10 -3 = 7
Observa-se que o conjunto de dados mais disperso ou menos homogêneo é o que possui maior amplitude.
DESVIO-MÉDIO (DM)
O grau de dispersão de um conjunto de observações pode ser medido pela média dos desvios dos dados em relação à média do conjunto de observações.
Exemplo: Consideremos os seguintes dados: 3; 7; 8 e 10.
- A média dos dados é igual a 7;
- Os desvios são da média são: (3–7); (7–7); (8–7) e (10 -7).
A média dos desvios (MD) é dada por:
A soma dos desvios será sempre zero, qualquer que seja o conjunto de dados. Um procedimento para solucionar esse problema é trabalhar com os valores dos desvios em módulo, assim sendo, temos o desvio-médio, porém, é menos conveniente que outras medidas estatísticas, como variância e desvio-padrão, para o estudo da variabilidade, porque perdemos valores quando o conjunto de dados é negativo.
VARIÂNCIA AMOSTRAL (s²)
O método mais utilizado para medir a dispersão dos dados é através da soma dos quadrados dos desvios, dessa maneira, temos o cálculo da variância, que é calculada pela seguinte equação:
- Para dados não agrupados — População:

- Para dados não agrupados — Amostra:

- Para dados agrupados:
Em que:
yi = são os valores observados, ou ponto médio das classes;
Ӯ = é a média dos dados da amostra;
N = é o tamanho da população ou número de elementos da população;
n = é o tamanho da amostra ou número de elementos da amostra;
fi = é a frequência de cada classe.
DESVIO-PADRÃO (s)
O desvio-padrão é definido como a raiz quadrada da variância. a variância apresenta a desvantagem de ter a unidade de medida elevada ao quadrado. Assim, se estamos tratando de altura de pacientes, teremos, por exemplo uma média de 1,65 m e uma variância 0,16 m². Portanto, para se voltar à unidade original, deve extrair a raiz quadrada de s², obtendo-se o desvio-padrão s, no caso s = 0,4 m.
ERRO-PADRÃO (sy)
O erro-padrão avalia a precisão do cálculo da média populacional. Quanto melhor a precisão no cálculo da média populacional, menor será o erro padrão.
COEFICIENTE DE VARIAÇÃO (CV)
O coeficiente de variação é uma medida relativa de dispersão utilizada para se comparar, em termos relativos, o grau de concentração em torno da média (dispersão). É definido como:
Se tivermos dois grupos, um com média 5 e desvio-padrão 4 e outro com média 70 e dispersão também 4, observa-se que a dispersão do primeiro grupo é relativamente grande se comparado com a média, por outro lado, no segundo grupo cuja média é 70, a dispersão é pequena em torno da média.
Assim, o CV para o primeiro grupo será igual a 40% e para o segundo 3%, ficando mais fácil de comparar a dispersão dos dois conjuntos de dados. No primeiro grupo a dispersão é alta enquanto que no segundo grupo a dispersão é baixa. Então, quanto menor o CV melhor a representatividade da média.
Alguns especialistas consideram:
- Baixa dispersão: CV ≤ 15%
- Média dispersão: 15% < CV < 30%
- Alta dispersão: CV ≥30%
O CV é útil na comparação de duas variáveis ou dois grupos que a princípio não são comparáveis (por exemplo, com ordens de grandeza das variáveis diferentes).
Exemplo 01:
Supondo que estamos estudando o peso de cães da raça Beagle, dada em kg. Foram observados cinco cães dessa raça e os pesos foram: 9,1; 9,5; 9,8; 10,2 e 11,0. Qual a variância, o desvio-padrão, o erro-padrão e o coeficiente de variação do peso desses animais? (média: Ӯ=9,92kg)
Resumo:
R: A variância foi igual 0,527kg², o desvio padrão foi de 0,726kg, o erro-padrão é 0,325kg e o coeficiente de variação foi de 7,32%.
* Atenção: não se esqueça de colocar a unidade ‘quilogramas’ após indicar o valor da média.
Exemplo 02:
Considere a distribuição de frequências do número de visitas anuais de 11 proprietários de cães a um pet-shop. E responda qual a variância, o desvio-padrão e o coeficiente de variação de visitas a esse pet-shop? (média: Ӯ=33,32 visitas)
Tabela 01: Distribuição de frequências do número de visitas anuais de 11 proprietários de cães a um pet-shop, no ano de 2017.
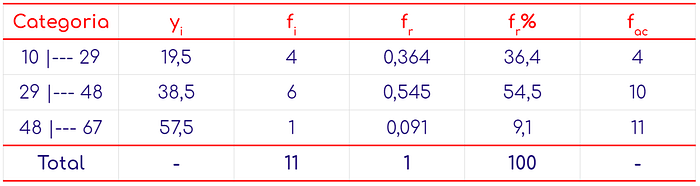
Fonte: próprio autor (dados fictícios). fi = frequência absoluta; fr = frequência relativa; fac = frequência acumulada.

Resumo:
R: A variância foi igual 150,96 visitas², o desvio padrão foi de 12,29 visitas, o erro-padrão foi 3,70 visitas e o coeficiente de variação foi de 36,88%.
Conclusão
O que Aprendemos Hoje:
- O que são as medidas de dispersão;
- A importância das medidas de dispersão;
- Calcular a variância, o desvio-padrão, o erro-padrão e o coeficiente de variação.
